

This paper uses reinforcement learning (RL) to approximate the policy rules of banks participating in a high-value payments system. The objective of the agents is to learn a policy function for the choice of amount of liquidity provided to the system at the beginning of the day. Individual choices have complex strategic effects precluding a closed form solution of the optimal policy, except in simple cases.
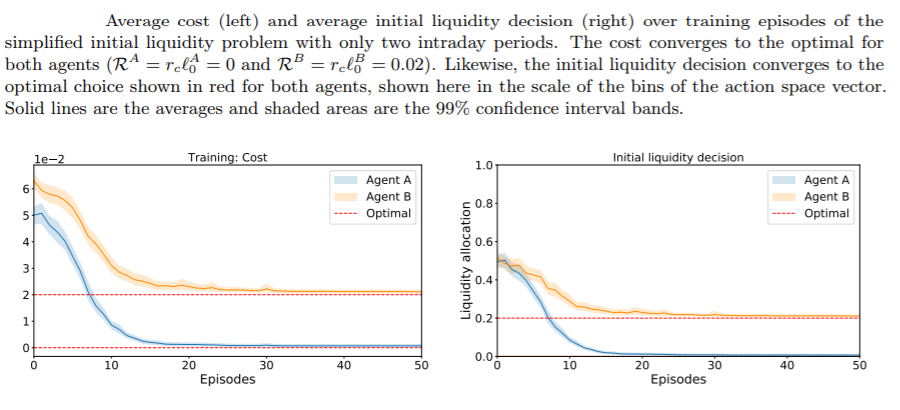
Researchers show that in a simplified two-agent setting, agents using reinforcement learning do learn the optimal policy that minimizes the cost of processing their individual payments. They also show that in more complex settings, both agents learn to reduce their liquidity costs.
Conclusion
These results show the applicability of RL to estimate best-response functions in real-world strategic games. The significance of these results are underlined by the fact that the initial liquidity decision of banks is complex even when agents have full knowledge of the environment, the data generating process and their opponent’s strategies.
The agents had no knowledge of the environment, the data, or the game itself. From a normative point of view, if agents trained with RL methods can find alternative solutions, regulators could use RL policies to help in their mandates of ensuring the safety and efficiency of these systems. Also, understanding these techniques will be relevant for policymakers as banks themselves are likely to attempt to use these algorithms for their liquidity management.
Before these promises can be realized, a more complete understanding of the liquidity management rules of financial institutions is needed. This paper is the first in that agenda. Future work will involve pursuing the following extensions.
First, it is important to explore how the agents would perform if they were learning the initial liquidity and intraday payment problems at the same time. Second extension is to tackle the problem with more than two-agents, which will require generalizing over more complex sets of payment demands to potentially derive richer policies that account for who a payment is being sent to and who a payment has been received from.
A major extension will be to introduce some realistic features of the payments system, like non-divisible or urgent payments, and an intraday market for liquidity. These could be significant departures to the learning setup that might require new algorithms and neural networks.