


Increasing the automation of securities finance and collateral management requires taking a joint technical and business perspective. Without it, firms could find themselves failing to progress or misdirecting IT investment. A guest post from Darren Crowther and Martin Walker of Broadridge.
It is far too easy in the world of securities finance to face two directions at once, unable to move forward. On the one hand you have those saying: “Securities finance is a relationship business, its simply not possible to automate most of what people do.” And on the other hand, there are the people who believe that: “Robotics, Machine Learning or Distributed Ledger Technology will automate everything.” The problem with both of those views is they have a strong element of truth but neither of them are the whole truth.
Exhibit 1 – Janus the Roman God of
Looking in Two Directions at Once

Securities Finance, particularly securities lending, really is a relationship business. Who to borrow securities from? Who to recall from? Who to share availability with? These and many other trading questions require consideration of both purely commercial and relationship factors. Repeatedly making the wrong decision may not immediately impact profits but will damage relationships and the long-term prospects for a business. At the same time, many firms have also made major progress in automating processes using new technologies, though it can be challenging matching the right technology with the right problem and ensuring return on IT investments when the eagerness for a technology exceeds its usefulness.
There is a middle path between technological scepticism and technological exuberance. Navigating that path in securities finance requires a genuine convergence of the business and technological perspective. A small number of people have worked in such depth in both technology and business that they can do it instinctively. Generally, it requires a team that combines expertise in both these areas, as well as an ability to communicate effectively despite those different perspectives.
Designing and implementing effective automation requires an understanding of some surprisingly straightforward concepts. These concepts already exist in the heads of traders, middle office and operations but do not usually have techy sounding labels attached to them, for example algorithms, data, variability and IPO (Input-Processing-Output).
Data is a much discussed topic, but any automated process requires good quality data and an understanding of what the data is and what it is used for. To take the example of cash marking in securities lending, the key data required is trade data (including security identifiers and trade quantities) and price data (including the security identifier of the relevant securities and the date the prices were captured). The resulting data from the marking process is primarily updated trades. Most fundamental IT processes consist of an Input, Processing and an Output, which in this example is the input of trade and prices, the processing of marking and the output being the updated trades.
Variability is a key concept that applies to all processes particularly those that require some human input. Think about a typical returns process. The key inputs are the long positions that need to be flattened by returning stock, a list of trades that can potentially be returned and the most variable input (and the one most relevant to relationship management), the potential attitude of lenders to having stock returned.
The final concept is the Algorithm. It is easy to get the impression that algorithms are incantations of fintech wizards. In reality an algorithm is simply a list of tasks required to achieve an objective. If you have ever followed a recipe to bake a cake you have followed an algorithm. The example below is for processing a margin call, but looked at as an algorithm is no more complicated than baking.
Exhibit 2 – Processing a Margin Call as an Algorithm
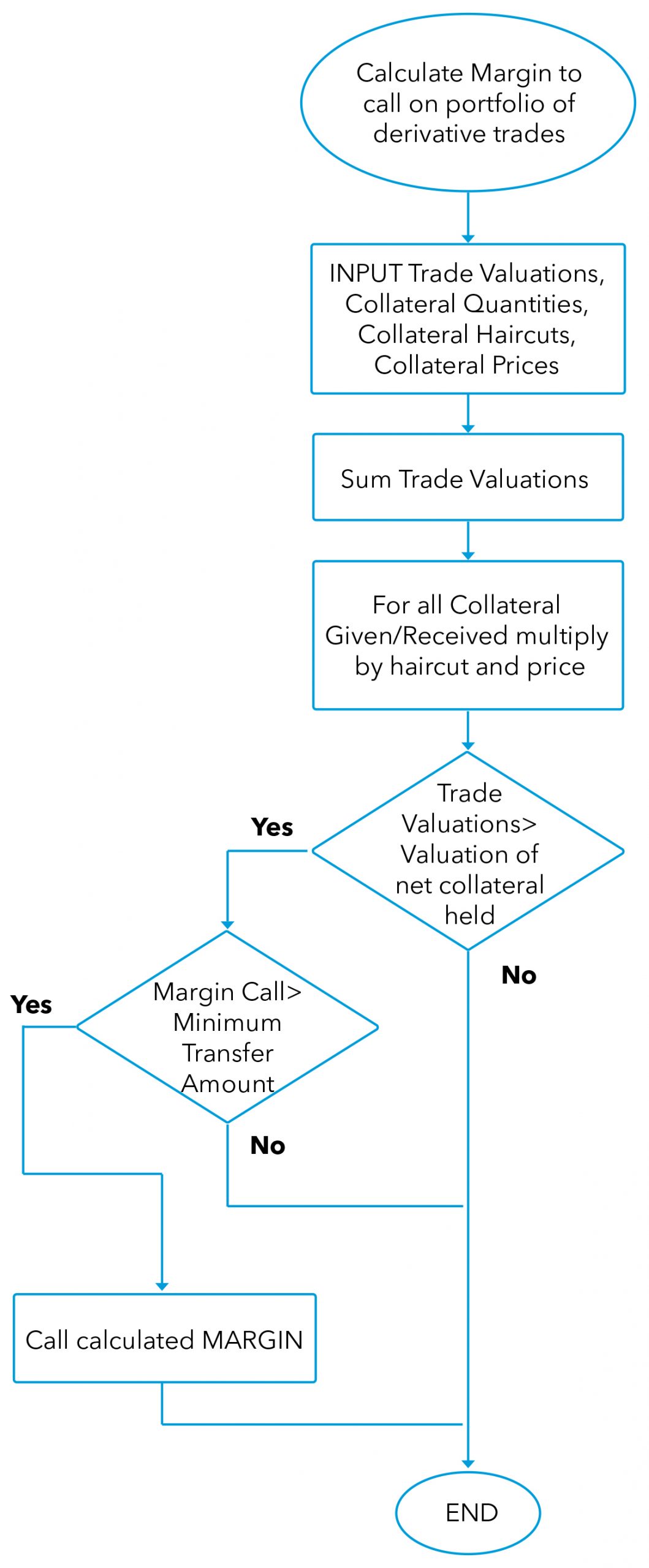
Source: Front-to-Back: Designing and Changing Trade Processing Infrastructure, Risk Books, ISBN 978-1-78272-389-9
Now that the reader is equipped with the core concepts of designing a system, we can think through automating some of those tricky relationships and high variability business processes. Let’s think through an example.
For example, the recalls process of calling back stock that has been lent out is superficially simple and easy to automate. Ideally a process should identify the short positions and the loans made for the same securities. It should then automatically recall the loans with the lowest fees on them. Unfortunately, nobody likes being recalled. There is the challenge of finding replacement stock, the operational cost of processing the return to the lender and the operational cost of borrowing replacement stock. The relationship algorithm (and it is an algorithm) operating in the mind of the trader is asking, “What is the reaction of the borrower going to be?”. “Will they be discouraged from borrowing from us in the future?” or “Will there be other relationship issues?”. These sensible questions are ultimately asked repeatedly, just as a computer runs the same algorithm in code thousands of times per day or even per second.
Ultimately data drives answers to the questions, even if the data is only stored in the head of the trader or perhaps exists in systems other than the trading system. Data that is stored in a trading system that could drive the process to recall includes:
- Profit and loss from previous trades related to the counterparty
- The number of times the borrower returns stock early or recalls (if they also lend stock)
- The duration to date of the trade (recalling stock that has been on loan for less than a minimum number of days may have a particularly damaging impact on relationships)
Other relevant data may not be in the core trading system but may be sourced from other systems (internal or external).
- The overall profitability of a borrower’s relationship with a firm, for instance the counterparty may also be a profitable client of the swaps desk
- The operational processes of the borrower may be less efficient than other counterparts and doing any kind of activity with them is likely to generate greater operational costs
- The borrower’s credit rating
Finally, there is data that is not currently stored, may not even be quantified and is subjective in nature. This information could be used to create a client ranking, which could be stored in a system and used in an algorithm:
- The counterparty may be a good source of market colour
- They may have a history of introducing new clients to the firm
- They are supportive of the firm in market surveys or prizes
Examine almost any process in securities finance that has a relationship angle and it will be possible to ultimately identify the algorithm a human being uses and the full set of data that is used by that algorithm to produce the desired result. This does not mean everything that can be automated should be automated. For some processes an algorithm plus the right data can prove superior to any human no matter how experienced or good at relationship management. In plenty of other examples humans are still the best solution because building systems and capturing the right data can be very expensive.
Overall, the viability of any business depends on automating what is most appropriate to automate and letting people focus on activities for which they add the most value. In securities finance, this means finding new business opportunities, structuring new products and creating new client relationships.
About the Authors
 Darren Crowther is the General Manager for Broadridge’s Securities Finance and Collateral Management division. Darren has over 17 years’ experience in the software business and has been involved with Securities Finance since 1998. He has been with Broadridge since the acquisition of 4sight in 2016. From 4sight’s beginning in 2003 Darren has served in a number of leadership roles. His most recent being Vice President of Solution Delivery, which he held from 2011 until the acquisition in 2016. Darren was instrumental in the setup and development of the original (SFCM) Securities Finance and Collateral Management solution.
Darren Crowther is the General Manager for Broadridge’s Securities Finance and Collateral Management division. Darren has over 17 years’ experience in the software business and has been involved with Securities Finance since 1998. He has been with Broadridge since the acquisition of 4sight in 2016. From 4sight’s beginning in 2003 Darren has served in a number of leadership roles. His most recent being Vice President of Solution Delivery, which he held from 2011 until the acquisition in 2016. Darren was instrumental in the setup and development of the original (SFCM) Securities Finance and Collateral Management solution.
 Martin Walker is the Head of Product Management for Broadridge’s Securities Finance and Collateral Management division. Former roles include Global Head of Securities Finance and Treasury IT at Dresdner Kleinwort and Global Head of Prime Brokerage Technology at RBS Markets. He has also worked as a consultant and researcher in capital markets with several papers published. He contributed to the new book, Evidence-Based Management – How to Use Evidence to Make Better Organizational Decisions, and his first book on Capital Markets infrastructure will be published later in the year. He has an MSc in Computing Science from Imperial College, London and a BSc in Economics from the London School of Economics. He is also a fellow of the Centre for Evidence-based Management.
Martin Walker is the Head of Product Management for Broadridge’s Securities Finance and Collateral Management division. Former roles include Global Head of Securities Finance and Treasury IT at Dresdner Kleinwort and Global Head of Prime Brokerage Technology at RBS Markets. He has also worked as a consultant and researcher in capital markets with several papers published. He contributed to the new book, Evidence-Based Management – How to Use Evidence to Make Better Organizational Decisions, and his first book on Capital Markets infrastructure will be published later in the year. He has an MSc in Computing Science from Imperial College, London and a BSc in Economics from the London School of Economics. He is also a fellow of the Centre for Evidence-based Management.
[i] Source – https://upload.wikimedia.org/wikipedia/commons/f/fb/Janus_coin.png
{kind=link}
[ii] “Front-to-Back: Designing and Changing Trade Processing Infrastructure” Risk Books